Does your high performing model degrade/perform poorly on an out of time sample? Has your Kaggle Private score come down from your Public score significantly? Not sure, if your current model is an overfit or the right fit? If your answer to any of the above three questions is “yes”, you have come to the right place. Recently, I participated in one of the Kaggle competition called TFI where I experimented a lot of things to get a sense of when do I overfit. I will illustrate my finding in this article.
Kaggle works on a very simple principle : You have train and test datasets. You are expected to build a model on train data and score test population. Once you score the test population, Kaggle scores your predictions on 30% of the testing population. Rest 70% is left to the end of competition. The initial 30% score is known as the Public score and rest called the Private score. So everyday you improve on your Public score by improvising your model but you will never know if you are over-fitting the population. This will only come to notice when the score for rest 70% is out, which is after the end of the competition. For the competition participation you need to submit only two solution which will be counted for Private Leaderboard.
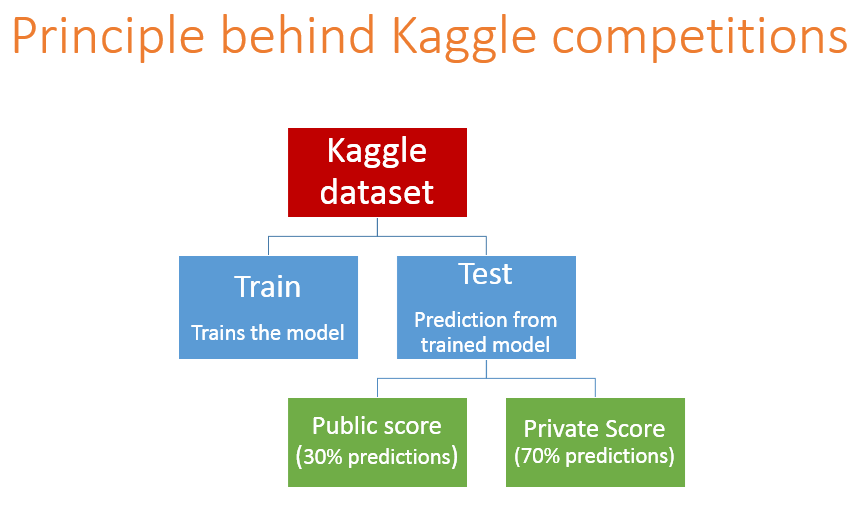
Here is an example of scoring on Kaggle!
For TFI competition, following were three of my solution and scores (Lesser the better) :
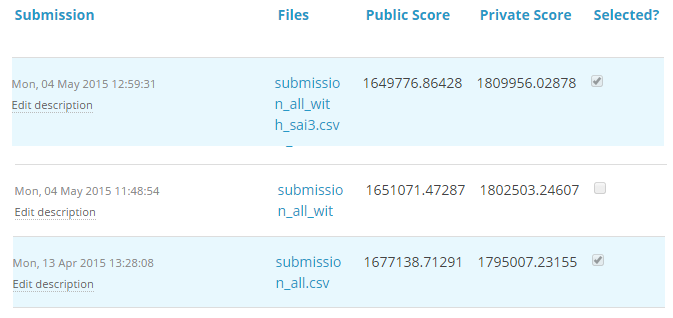
You will notice that the third entry which has the worst Public score came out to be the best model on Private ranking. There were more than 20 models above the “submission_all.csv”, but I still chose “submission_all.csv” as my final entry (which really worked out well). In the following section I will discuss how you can know if a solution is an over-fit or not before we actually know the test results.
The concept : Cross Validation
Cross Validation is one of the most important concepts in any type of data modelling. It simply says, try to leave a sample on which you do not train the model and test the model on this sample before finalizing the model.
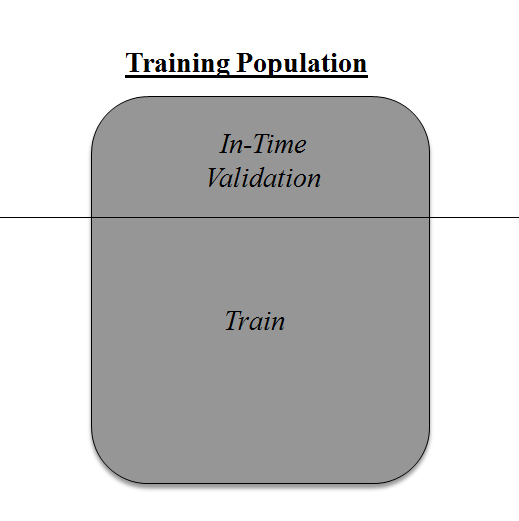
Above diagram shows how to validate model with In-time sample. We simply divide the population into 2 samples, and build model on one sample. Rest of the population is used for in-time validation.
Thinkpot : Think of the bad side of the above approach?
Bad side of the approach is that we loose a good amount of data from training the model. Hence, the model is very high bias. And this won’t give best estimate for the coefficients. So what’s the next best option?
What if, we make a 50:50 split of training population and the train on first 50 and validate on rest 50. Then, we train on the other 50, test on first 50. This way we train the model on the entire population, however on 50% in one go. This reduces bias because of sample selection to some extent but gives a smaller sample to train the model on. This approach is known as 2-fold cross validation.
k-fold Cross validation
Let’s extrapolate the last example to k-fold from 2-fold cross validation. Now, we will try to visualize how does a k-fold validation work.

This is a 7-fold cross validation. Here’s what goes on behind the scene : we divide the entire population into 7 equal samples. Now we train models on 6 samples (Green boxes) and validate on 1 sample (grey box). Then at the second iteration we train the model with a different sample held as validation. In 7 iterations, we have basically built model on each sample and held each of them as validation. This is a way to reduce the selection bias and reduce the variance in prediction power. Once we have all the 7 models, we take average of the error terms to find which of the models is best.
How does this help to find best (non over-fit) model?
k-fold cross validation is widely used to check whether a model is an overfit or not. If the performance metrics at each of the k times modelling are close to each other and the mean of metric is highest. In a Kaggle competition, you might rely more on the cross validation score and not on the Kaggle public score. This way you will be sure that the Public score is not just by chance.
How do we implement k-fold with any model?
Coding k-fold in R and Python are very similar. Here is how you code a k-fold in Python :
from sklearn import cross_validation model = RandomForestClassifier(n_estimators=100)
#Simple K-Fold cross validation. 5 folds.
#(Note: in older scikit-learn versions the "n_folds" argument is named "k".)
cv = cross_validation.KFold(len(train), n_folds=5, indices=False)
results = []
# "model" can be replaced by your model object # "Error_function" can be replaced by the error function of your analysis
for traincv, testcv in cv:
probas = model.fit(train[traincv], target[traincv]).predict_proba(train[testcv])
results.append( Error_function )
print out the mean of the cross-validated results
print "Results: " + str( np.array(results).mean() )
But how do we choose k?
This is the tricky part. We have a trade off to choose k.
For a small k, we have a higher selection bias but low variance in the performances.
For a large k, we have a small selection bias but high variance in the performances.
Think of extreme cases :
k = 2 : We have only 2 samples similar to our 50-50 example. Here we build model only on 50% of the population each time. But as the validation is a significant population, the variance of validation performance is minimal.
k = number of observations (n) : This is also known as “Leave one out”. We have n samples and modelling repeated n number of times leaving only one observation out for cross validation. Hence, the selection bias is minimal but the variance of validation performance is very large.
Generally a value of k = 10 is recommended for most purpose.
End Notes
Measuring the performance on training sample is point less. And leaving a in-time validation batch aside is a waste of data. K-Fold gives us a way to use every singe datapoint which can reduce this selection bias to a good extent. Also, K-fold cross validation can be used with any modelling technique.
Were you haunted by any questions/doubts while learning this concept? Ask our analytics community and never let your learning process stop.
Have you used k-fold cross validation before for any kind of analysis? Did you see any significant benefits against using a batch validation? Do let us know your thoughts about this guide in the comments section below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.






I recently used 10-fold cross-validation with 5 repeats using a K nearest neighbours algorithm on a training set, and selected the best model to predict on my testing data for a Kaggle competition. While my training set scored approximately 0.92 resampled AUC, the testing set only scored approximately 0.82 on Kaggle. While other models I've tried have had similar accuracy between resampled and testing set AUC, this model seemed to really struggle on the testing set. Could this have something to do with the KNN algorithm in particular, or something more general with cross-validation?
Hi @tycragg do you mean that the difference between .92 and .82 was the gap between your public and private scores for your submitted solution?
Please enlighten me if wrong, RandomForest uses OOB estimate while doing bootstrapping which is inline with k-fold cross validation ?